
삶의 공유
[ML] Ensemble(앙상블) 기본 다지기 본문
Ensemble, 한국어로 앙상블이라고 읽는 이 Ensemble 모델은 대표적인 분류 모델 중 하나이다.
어원으로는 함께, 동시에, 협력하여 등을 뜻하는 프랑스어. 영어로는 합창단, 무용단, 합주단 등을 의미한다. 많은 수의 작은 악기소리가 조화를 이루어 더욱 더 웅장하고 아름다운 소리를 만들어낸다. 물론 그래서는 안 되겠지만, 한 명의 아주 작은 실수는 다른 소리에 묻히기도 한다.

기계학습에서의 앙상블도 이와 비슷하다. 여러 개의 weak learner들이 모여 투표 (voting)를 통해 더욱 더 강력한 strong learner를 구성하고 많은 모델이 있기 때문에, 한 모델에서 예측을 엇나가게 하더라도, 어느 정도 보정이 된다.
즉, 보다 일반화된 (generalized) 모델이 완성되는 것이다.
단일 모델로는 Decision tree, SVM, Deep learning 등 모든 종류의 학습 모델이 사용될 수 있다.
Ensemble Overview
머신 러닝 기법으로의 Ensemble(앙상블)은 다음과 같은 의미를 가진다.
- 어떤 데이터를 학습 할 때, 여러개의 모델을 조화롭게 학습 시켜 그 모델들의 예측 결과들을 이용하여 더 정확한 예측 값을 구할 수 있음
앙상블 모델과, 단일 모델에 대해 잘 정리된 모식도를 살펴보면 다음과 같다.
단일 모델의 단점을 보완하기 위해 더욱 발전 된 형태가 앙상블 형태이다. 이렇듯 여러개의 독립적인 모델들을 바탕으로 더욱 정확한 예측값을 구할 수 있는 것이다.
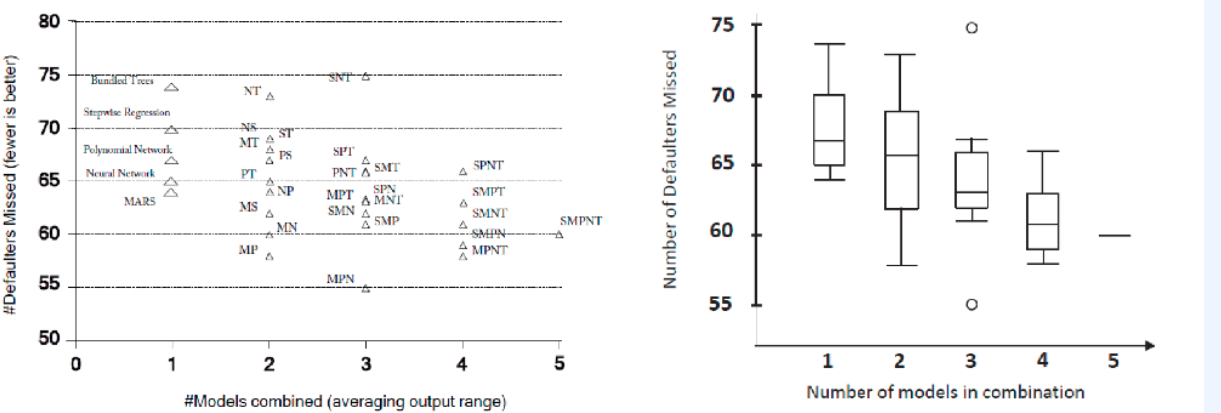
또한 여러개의 모델 개수에 따른 에러율에 대한 성능에 대한 그래프를 나타내면 아래 그림처럼 모델 개수가 늘어 날 수록 에러가 낮아지는 것을 볼 수 있다.
앙상블에 대한 논문 중 재미있는 주제의 논문을 소개해보려고 한다.
▶ Ensembles almost always work better
이 논문은 바로 앙상블 모델이 Single모델 보다는 에러가 항상 작거나 같다 라는 것을 수식적으로 증명한 논문이다.
수학적으로 관심이 있으신 분들은 위 논문을 검색해서 확인해 보면 좋을 것 같다.

이 뿐만 아니라 2014년에 한 눈문에서는 121개의 공개 Data set에 179개의 알고리즘을 적용 하여 분류 성능을 비교 시, Random Forest(의사 결정 나무의 앙상블)와 SVM 계열이 상대적으로 분류 성능이 높은 것으로 확인이 되었다.
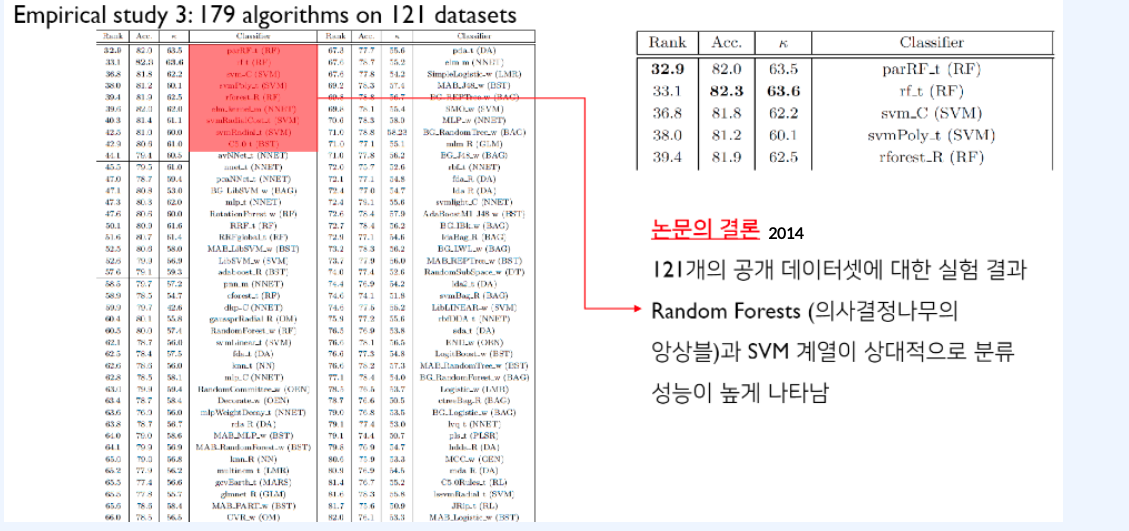
하지만 주의할 점은 어떤 알고리즘도 모든 상황에서 다른 알고리즘보다 우월하다는 결론을 내릴 수 없다는 점이다.
즉, 문제의 목적, 데이터의 형태 등을 종합적으로 고려하여 최적의 알고리즘을 선택 할 필요가 있다.
Ensemble 종류
앙상블의 종류에는 3가지 종류가 있다.
1. Bagging (Reduce the Variance)
2. Stacking (Use another prediction model)
3. Boosting (Reduce Bias)
자 각각에 대해 알아보기 전에 Variance, Bias가 무엇인지 살펴보자.
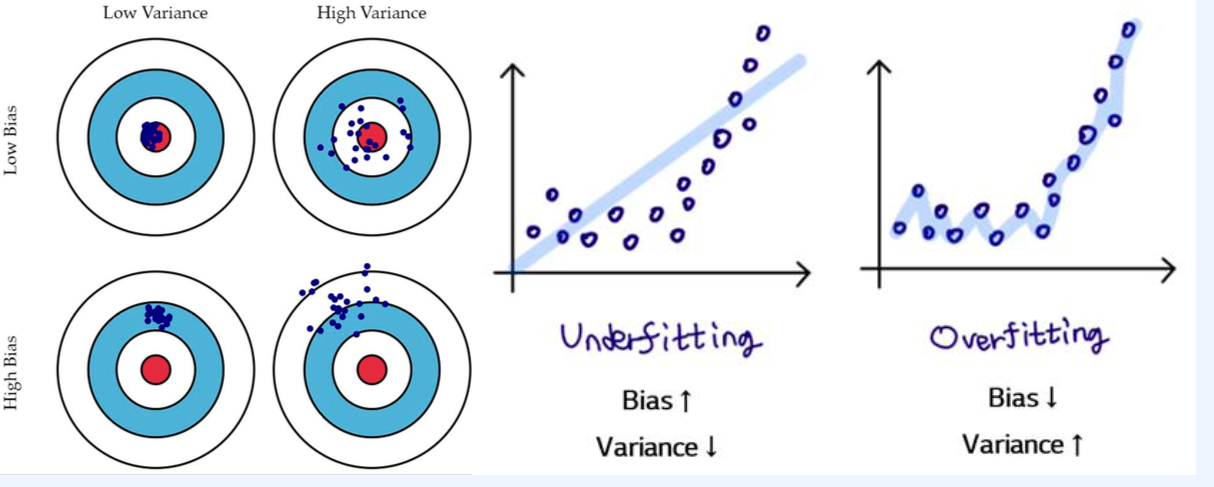
아래 그림이 가장 잘 설명된 그림이라 가져와보았다.
- Variance (분산) : 분산이라는 의미 인것 처럼 각각의 분산이 커질 수록 타점들이 더욱 넓게 형성이 된다고 생각 하면 된다.
- Bias : 목표(빨간색 영역) 대비 얼마나 떨어져 있는지를 나타내는 것 이라고 생각 하면 된다.
Bagging(Bootstrap Aggregating)
Bagging이란, 기존 학습 데이터(Original Data)로부터 랜덤하게 '복원추출'하여 동일한 사이즈의 데이터셋을 여러개 만들어 앙상블을 구성하는 여러 모델을 학습시키는 방법이다. 이러한 복원추출로 만들어진 새로운 데이터셋을 'Bootstrap'이라고 한다.
요렇듯 Original Dataset에 10 개의 Data가 있으면 10개를 Randomly 하게 뽑아 내서 새로운 Data set을 구성(Bootstrap) 하는 것으로 생각하면된다.
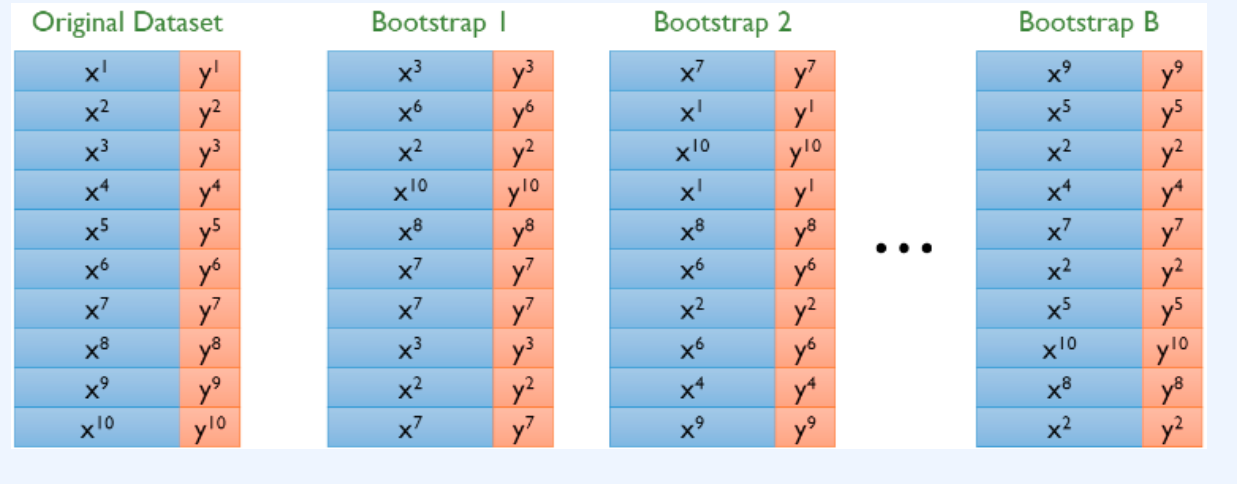
기존 데이터(Original 데이터)는 노이즈(epsilon)의 분포에 의존적인데, 복원추출을 함으로써 각Bootstrap이 기존의 노이즈와는 조금씩 다른 노이즈 분포를 갖도록 변형을 주는 것이다. 기존 데이터셋만 사용하여 학습했을 때는 하나의 특정한 노이즈에만 종속적인 모델이 만들어질 수 있는 위험이 있다. 그러나 Bagging은 조금씩 분포가 다른 데이터셋을 기반으로 반복적인 학습 및 모델 결합을 통해 이러한 위험을 방지하는 효과를 가진다.
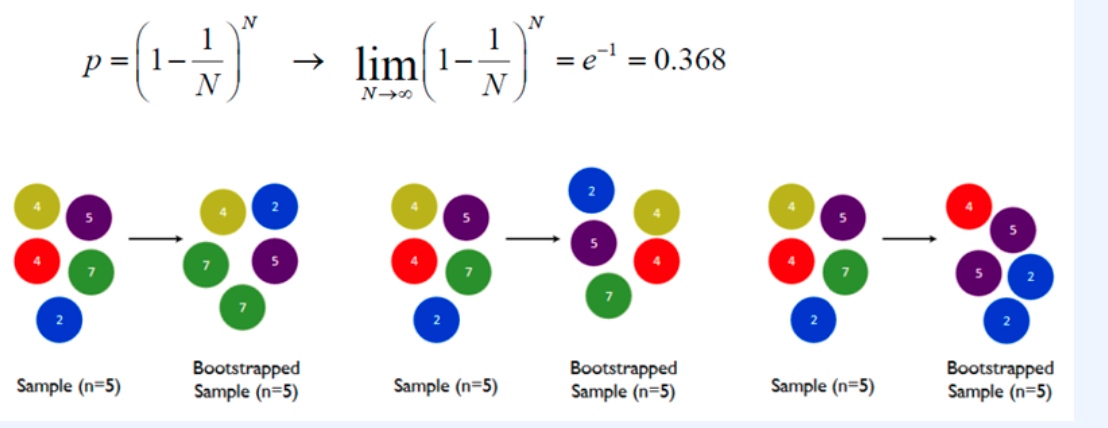
하지만 위 그림의 Bootstrap1을 보면, 복원추출로 인해 x2, x3, x7은 중복되어 들어간 것을 볼 수 있다. 반면에 x1, x4, x5, x9는 아예 포함되어 있지 않다. 이러한 Bootstrap들이 가지는 의미는 무엇일까? 복원추출로 인해 각 Bootstrap들은 기존 데이터와는 다른, 즉 (긍정적으로) 왜곡된 데이터 분포를 갖게 된다
진행 횟수를 무한대로 보냈을 때 포함 되어있지 않을 데이터에 대한 확률을 계산하면 36.8% 이다. 즉, 전체 데이터 중 36.8%는 뽑히지 않는다는 의미이다.
※ 이 36.8%가 어떻게 활용되는지에 대해서는 다음 Random Forest 포스팅 할때 자세히 설명할 예정이다. 지금은 이정도만 기억 하면 될 것 같다.
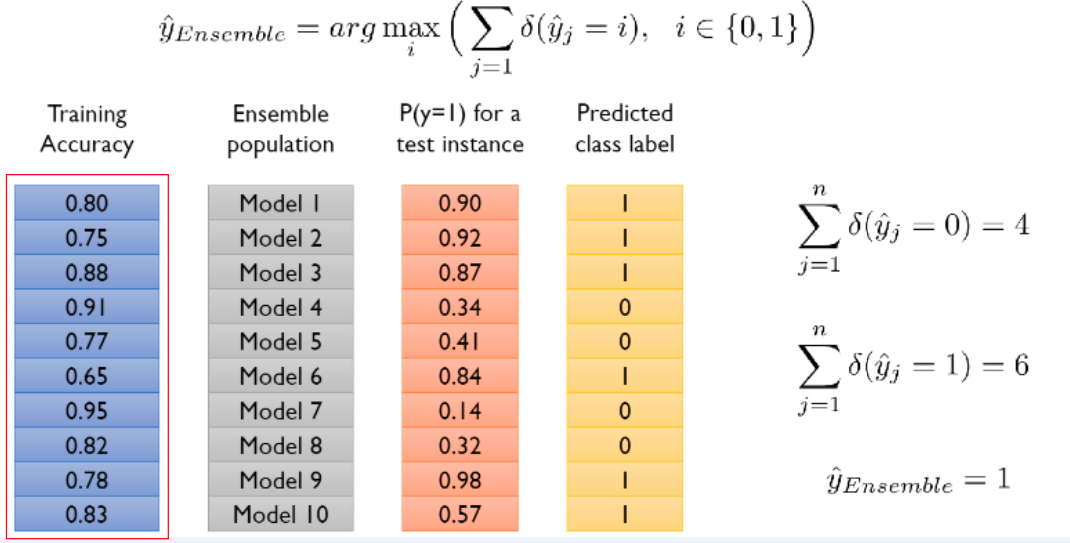
자 이제 각 Boostrap 데이터 셋을 이용하여 학습한 모델들을 조합하여 답을 예측 하는 방법에 대표적으로 Majority Voting 이 있다.
Majority Voting 방법은 일반적으로 가장 많이 사용 된다.
앙상블 모델이 예측하는 값의 개수에 대한 비율로 나타낸다. 아래 예시를 보면 각 모델이 예측한 class label이 1이 6개, 0이 4개 로 예측 을 하였다. 여기서 1이 6개로 다수를 차지하여 예측 값을 1로 예측 한다는 개념으로 Majority Voting 이라고 칭한다.
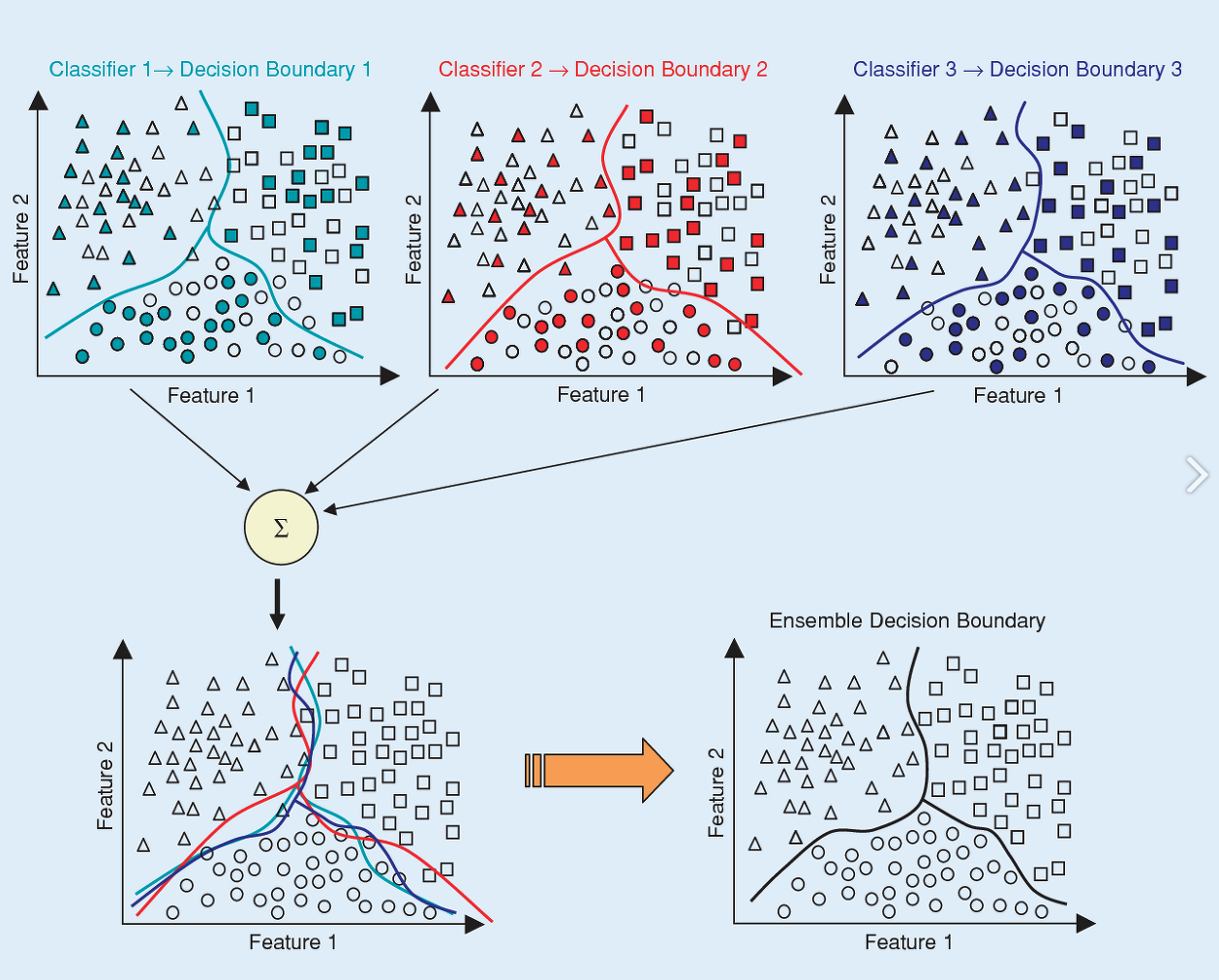
아래 그림은 Bagging 과정에 시각적으로 가장 잘 표현한 그림으로 한 논문에서 발췌해서 가져와보았다.
하늘색(Classifier1), 빨간색(Classifier2), 파란색(Classifier3)으로 색칠된 도형들은 각 Bootstrap에 포함된 데이터를 의미하며, 하얀색 도형들은 각 Bootstrap에서 제외된 OOB(Out of Bag) 데이터를 나타낸다. 각 그래프의 실선은 학습 모델의 분류 경계선을 나타낸다. 개별 모델들의 분류 경계선은 전체 데이터의 관점에서는 정확도가 떨어지지만, 이를 결합(Aggregation)한 모델(왼쪽 하단의 그래프)은 전체 데이터의 분포에 대해서 좀 더 정확한 분류 경계선을 갖는 것을 확인 할 수 있다.
※ 각 Bootstrap별로 포함되지 않은 데이터들의 집합을 OOB(Out of Bag) 데이터라고 부른다.
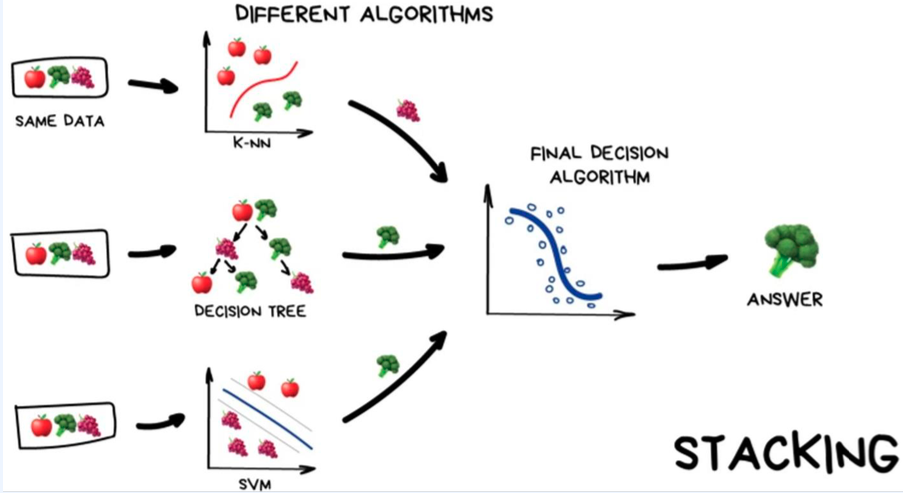
Stacking
스태킹은 여러 가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 예측하는 방법이다.
간단한 예시를 아래 그림과 함께 공부해보자
같은 데이터 셋을 K-NN, DECISION TREE, SVM 모델을 이용해서 예측값을 산출하고 그것을 Majority Voting을 통해서 최종 결과값을 산출 하는 것이라고 생각하면 됩니다.
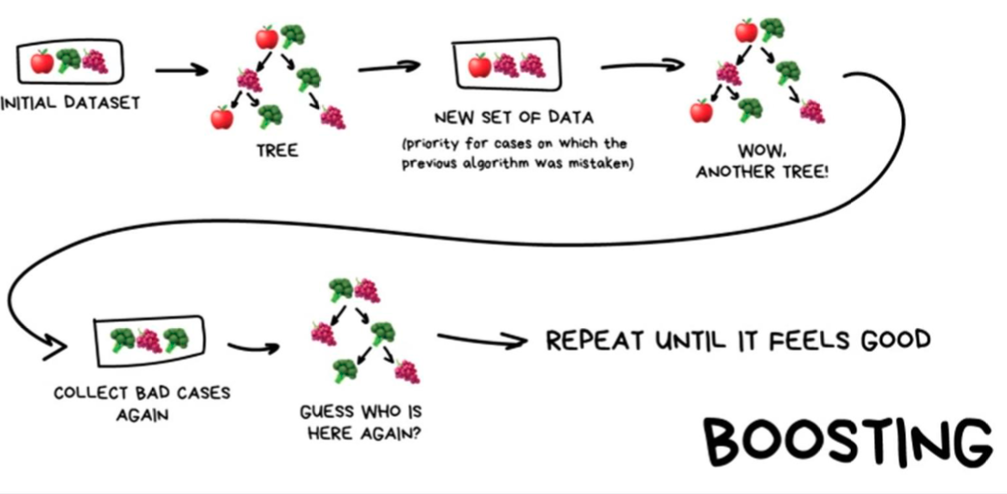
Boosting
위에서 Boosting 옆에 가로치고 Reduce the bias라고 써져있는 것을 보셨을 텐데, 타점을 과녘에 맞게 이동시키는 개념이라고 보면 된다. 즉 부스팅은 오차를 줄이기 위해 사용되는 학습 방법으로 앙상블 기법 중 하나로 약한 모델 여러개를 결합하여 성능을 높이는 알고리즘이다.배깅과의 다른 점은 배깅이 여러 데이터셋으로 나눠 학습을 한다면 (동시, 병렬 학습) 부스팅은 데이터셋 모델이 뒤의 데이터셋을 정해주고 앞의 모델들을 보완해 나가며 학습시켜 나간다. (순차, 직렬 학습) 때문에 시간이 보다 오래 걸리고 해석이 어렵다는 단점이 있다.
대표적인 Boosting을 이용한 모델로 XGBoost, LightGBM 모델이 있다.
'Data Scientist > ML' 카테고리의 다른 글
| [ML] Decision Tree (결정트리) 기본 다지기 (0) | 2024.02.05 |
|---|