
- 분류 전체보기 (348)

삶의 공유
[파이썬] 공공 데이터포털 API를 이용하여 수출입 데이터 가져오기 본문
안녕하세요 ~
오늘의 포스팅은 공공데이터 포털의 API를 이용하여 수출입 데이터 를 가져와 보려고 합니다.
1. 공공데이터 포털 가입 및 API 신청
먼저 아래의 사이트에 들어가셔서 회원 가입을 합니다.
https://www.data.go.kr/index.do
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
메인 페이지 에서 "수출입" 을 검색 합니다.

그러면 아래와 같은 API가 검색이 될거에요 그럼 여기서 활용신청을 누르고
※중요 : 아래 내용은 수출입 총괄이지만(제가 미리 신청을해놔서..), 실제 데이터를 가져올 것은 "관세청_품목별 국가별 수출입실적(GW)" 이거 입니다!

아래 항목에 목적을 작성 하시고 마지막에 활용신청을 누르시면 자동승인이 됩니다.
활용 신청을 누르면 이렇게 인증키 (서비스키)를 받을 수 있습니다.
2. 파이썬을 이용해서 데이터 호출
참고 문서에 나온 예시에 따라서 호출을 해보겠습니다. 먼저 파라미터들을 살펴보겠습니다.
필수 항목으로 되어 있는, 인증키 / 시작년월 /종료년월/ 국가코드는 꼭 넣어줘야합니다. 이제 이 항목들을 변수로 만들어서 파이썬 코드로 작성해보겠습니다.
import requests
import pprint
import json
servicekey = "여러분의 인증 코드(Encoding)를 입력하시면 됩니다."
strtYymm = 201601 # 시작년월
endYymm = 201601 # 종료 년월
hsSgn = "1001999090" # 품목 코드
cntyCd = "US" # 국가 코드
url = "http://apis.data.go.kr/1220000/nitemtrade/getNitemtradeList?strtYymm={0}&endYymm={1}&hsSgn={2}&cntyCd={3}&serviceKey={4}".format(strtYymm,endYymm,hsSgn,cntyCd,servicekey)
response = requests.get(url)
contents = response.text
contents- 정상적으로 동작이 된다면 나오는 응답 메시지

- 자 파이썬을 실행해보면 아래와 같이 잘 나오는 것을 볼 수 있습니다.

3. 데이터 정제
자 이렇게 추출한 데이터는 xml 형식으로 되어 있기 때문에 딱 보기에도 너무 어려워 보이지 않으신가요 ?
그럼 이제 파이썬을 활용해서 이 xml형식을 table형태의 데이터로 바꿔주어서 좀더 데이터 분석에 용이한 형태로 변형하겠습니다.
자 그럼 데이터가 어떤 형태로 있었는지 확인을 해볼까요 ? 이것도 참고 문서 에 있습니다.
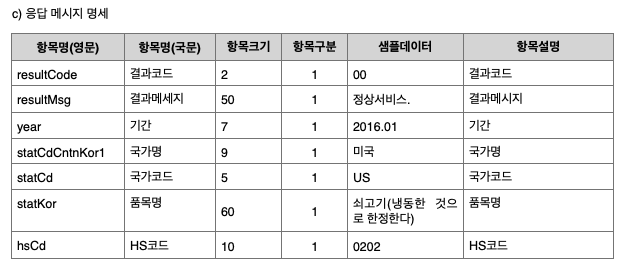
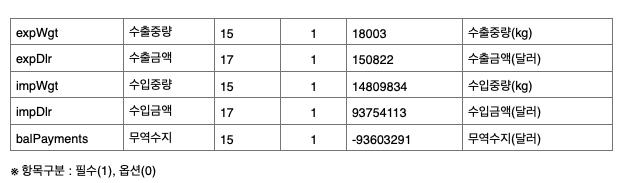
짜잔 이렇게 있습니다. 자 이제 여기서 저희가 가져올 데이터만 추려 봐야겠지요 ?
우선 저는 결과코드, 결과메세지를 제외하고 다 가져와보겠습니다.
1. 자 이제 파이썬에 내장되어 있는 xml 데이터를 처리할 수 있는 모듈을 이용해 보겠습니다.
바로 xml이라는 모듈인데요,
from xml.etree import ElementTree as ET
tree = ET.fromstring(response.content)
ET.dump(tree)자 이제 위에서 읽은 내용을 xml 객체로 만들어서 다시 읽어온것이에요 ! 이렇게 하는 이유는 나중에 pandas 라이브러리를 이용해서 dataframe으로 변환하기 용이 하기 때문입니다.

2. 자 이제 tree객체에서 우리가 원하는 항목인 item항목만 가져오겠습니다.
items = tree[1][0]
listofitems = [[i.text for i in item] for item in items]
무슨 말인지 잘 모르시겠죠? ㅎㅎ
tree[1][0]의 의미 부터 알아보겠습니다. 먼저 tree[1]의 의미는 body영역을 가져 오겠다 라는 의미 입니다.
xml구조는 이렇게 크게 2개의 카테고리로 나뉘어져 있습니다 그리고 그 뒤의 tree[1][0]의 의미는 body의 첫번째 항목들인 items를 가져오겠다라는 의미이구요!
이해가 되셨나요? 결국의 tree[1][0]의 의미는 items의 각 항목들을 골라 가져오겠다 라는 뜻입니다.

listofitems는 위에서 가져온 items 항목들을 for 문을 이용해서 하나씩 접근해서 그거를 리스트에 저장하겠다라는 뜻입니다.
items는 2개의 리스트를 가지고 있습니다. 첫번째는 항목별 총계에 대한 항목, 두번째는 각 항목에 대한 list입니다.
저희는 샘플로 미국의 쇠고기 항목에 대한 것만 가져왔기 때문에 1개밖에 출력이 안된거구요 ! 그래서 이렇게 for구문으로 만들어 두면 나중에 항목이 더 늘어놔도 해당 코드를 사용할 수 있습니다.
- Items[0]

- Items[1]

3. 자 이제 데이터의 컬럼명을 가져오겠습니다.
이거는 쉽죠? ㅎㅎ tag명을 가져와서 리스트에 저장하겠다는 코드입니다.
columns = [i.tag for i in items[0]]4. 이제 마지막입니다. 위에서 만들어놓은 listofitems와 columns를 pandas 라이브러리를 이용해서 dataframe으로 만들겠습니다.
df = pd.DataFrame(listofitems, columns=columns)
df
짜잔! 잘 나온것을 볼 수 있습니다.
그럼 오늘의 포스팅을 마치도록 하겠습니다.
다음 포스팅에서는 이렇게 뽑은 데이터를 시각화하여 분석 해보겠습니다.
'Data Scientist > Python' 카테고리의 다른 글
| 파이썬으로 이더리움 가격 예측하기(시계열 예측 라이브러리, prophet) (0) | 2023.01.18 |
|---|---|
| 파이썬을 이용하여 웹에서 금융 데이터 다운 및 시각화 (0) | 2022.12.20 |
| [파이썬] 투자를 위한 경제 지표 데이터 수집 및 시각화 (장, 단기 금리) (0) | 2022.09.04 |
| [Python] Turtle 객체를 이용하여 그림 그리기 (0) | 2022.08.15 |
| [Python] brute함수를 이용하여 자동 매매 이동평균선 전략 최적화 하기 (0) | 2022.06.07 |
