
삶의 공유
[Python기초] Matplotlib로 시각화 다루기 본문
이번 포스팅에서는 Matplotlib에 대해서 같이 공부해보도록 하겠습니다.
Matplotlib는 데이터들을 시각화 하여 분석에 좀 더 직관적으로 보일 수 있게 해주는 것 라이브러리라고 보시면 됩니다.
1. Line Plot
데이터는 구조는 다음과 같습니다. 이것을 가지고 시간에 따른 AAPL의 주가 변동 현황을 Line plot으로 그려보겠습니다.
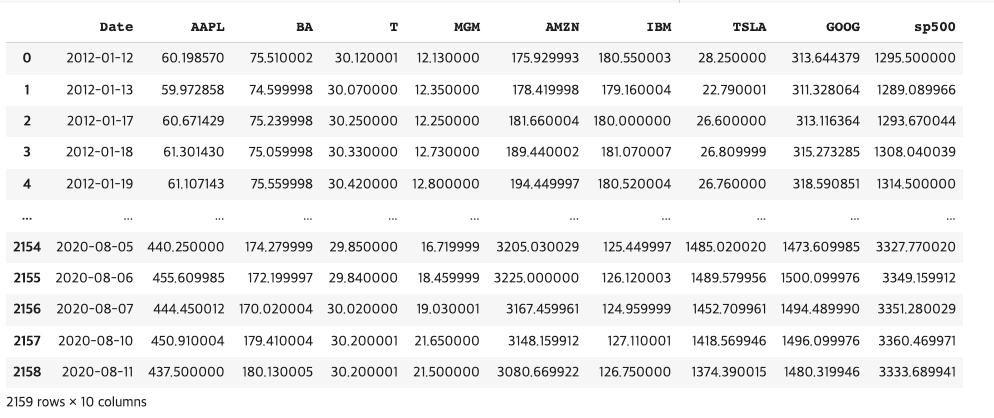
해당 데이터 프레임(stock_df)에서 바로 matplotlib를 호출 할 수 있습니다. 이는 pandas내에 matplotlib 기능이 포함이 되어있기 때문입니다. 어떤 기준으로 설정했는지 같이 한번 살펴보겠습니다.
- x축에 'Date' 컬럼을 설정
- y축게 'AAPL'의 주가를 설정
- label에 'APPLE Stock price'
- linewidth는 굵기 설정
stock_df.plot(x = 'Date', y = 'AAPL', label = 'APPLE Stock Price', linewidth = 3);
plt.ylabel('Price')
plt.title('My first plotting exercise!')
plt.legend(loc="upper left")
plt.grid()자 이렇게 작성한 코드가 어떻게 표현되는지 살펴보자. 원하는 대로 잘 나오는 것을 볼 수 있다.
2. SCATTER Plot
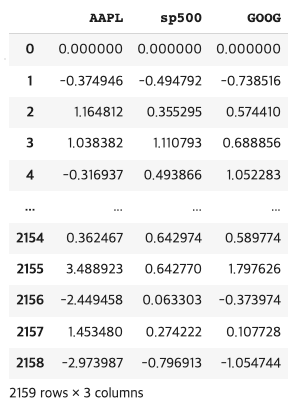
해당 예제에서의 데이터 구조는 다음과 같습니다.

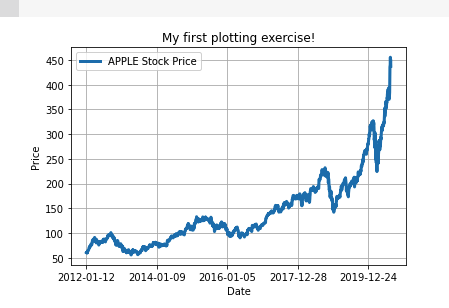
이번에는 S&P 500과 AAPL 주가와의 관계를 한번 살펴보겠습니다.
이번에는 데이터프레임에서 바로 matplotlib를 설정하는 것이 아니라, x축에는 daily_return_df의 'AAPL' 컬럼을 대입하고 y축에는 daily_return_df['S&P500'] 컬럼의 값을 대입하게 됩니다.
x = daily_return_df['AAPL']
y = daily_return_df['sp500']
plt.scatter(x, y)
plt.ylabel('S&P500 return')
plt.xlabel('Apple return')이렇게 matplotlib에서 직접 scatter를 호출하고 x, y값을 넣어주면 끝 ! 이렇게 작성한 코드가 어떻게 보이는제 같이 한번 보겠습니다.
3. Pie Plot
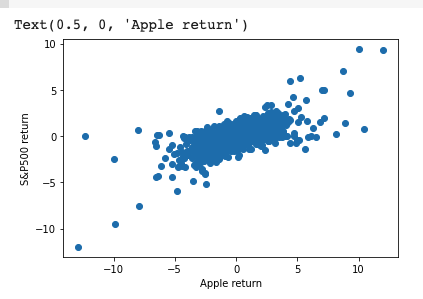
원형 차트를 그리고 어떻게 강조처리를 해서 데이터를 시각화 하는지를 살펴보겠습니다.
- 변수들을 정의합니다.
- values = 수치(비율)
- colors = 표현할 도형 색
- label = 해당 수치의 별명
- explode = 강조의 크기 (0 이 제일 작은 수치이며 점점 올라갈수록 강조의 넓이가 더 넓어짐(아래 "AMZN" 그림을 보면 이해하기 편합니다.)
values = [20, 55, 5, 17, 4]
colors = ['g', 'r', 'y', 'b', 'm']
labels = ['AAPL', 'GOOG', 'T', 'TSLA', 'AMZN']
explode = [0, 0, 0, 0,0.2]
plt.figure(figsize=(7,7))
plt.pie(values, colors = colors, labels=labels, explode=explode)
plt.title('STOCK Portfolio')
4. Histogram
어떻게 히스토그램을 시각화 하는지 살펴보겠습니다.
데이터 구조는 다음과 같은 데이터 구조를 사용하여 히스토 그램을 그려볼 것 입니다. 자 이제 아래 코드를 보면서 각 항목들이 뭘 의미하는지 Histogram 시각화에 어떤 작용을 했는지를 살펴보겠습니다.
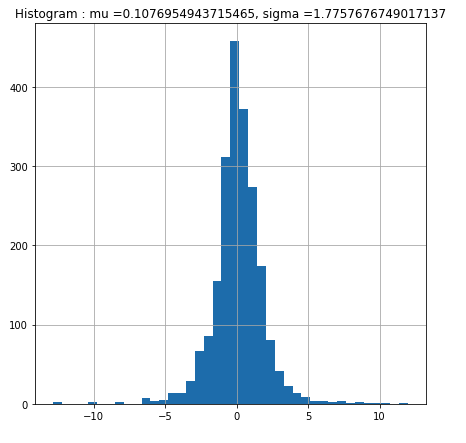
- num_bins=40의 의미는 x축을 40개의 구간으로 나누겠다는 의미입니다.
- figsize=(7,7)의 의미는 시각화를 표현할 크기를 설정하는 의미 입니다.
- plt.hist(daily_return_df['AAPL']) 이것의 의미는 daily_return_df['AAPL']을 Data로 사용 하겠다는 뜻입니다.
- plt.grid() 의 의미는 시각화에 그리드 (격자모양)을 그려넣겠다는 의미입니다.
import matplotlib.pyplot as plt
num_bins = 40
plt.figure(figsize=(7,7))
plt.hist(daily_return_df['AAPL'], num_bins)
plt.grid()
plt.title('Histogram : mu =' + str(mu) + ', sigma =' + str(sigma))※ mu = 평균
※ sigma = 표준편차
mu = daily_return_df['AAPL'].mean()
sigma = daily_return_df['AAPL'].std()위의 코드들을 실행하면 다음과 같이 시각화가 잘 표현 된 것을 볼 수 있습니다.
5. Multiple Plots
다음은 데이터프레임 객체에서 여러 컬럼들을 이용하여 x축과 y축을 나누어 다중 그래프를 구현해보겠습니다.
데이터 구조는 다음과 같습니다.
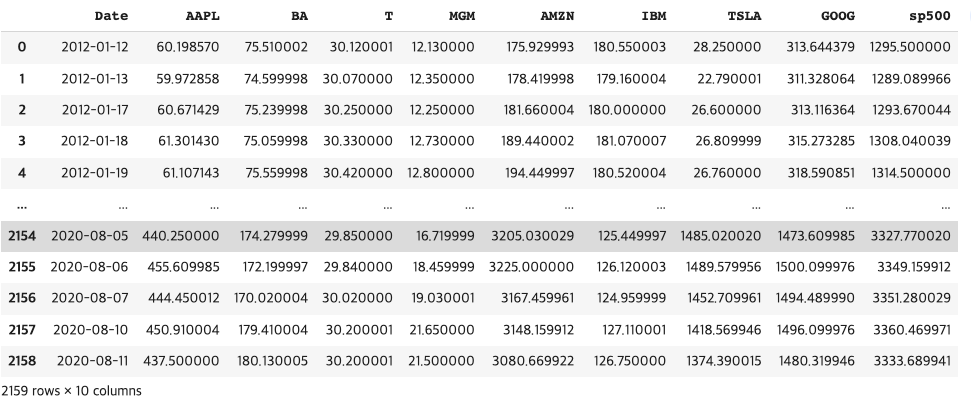
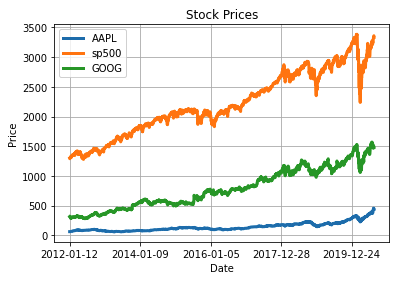
- stock_df의 데이터 프레임 객체에서 바로 .plot으로 함수를 호출합니다.
- x축에는 'Date' 컬럼을 y축에는 리스트로 'AAPL', 'sp500', 'GOOG'를 넣어주어 다중 그래프를 표현 합니다.
- linewidth는 선의 굵기 입니다.
stock_df.plot(x = 'Date', y=['AAPL', 'sp500', 'GOOG'], linewidth=3)
plt.ylabel('Price')
plt.title('Stock Prices')
plt.grid()위 코드를 실행하면 하기와 같이 잘 나오는 것을 볼 수 있습니다.
이번에는 한그래프안에 여러 데이터를 표시하는 것이 아니라 여러 데이터를 각 하나씩 여러 그래프에 시각화 하는 법에 대해서 배워보겠습니다. 바로 subplot함수를 이용하는 것 입니다. 해당 함수의 정의의 내용은 다음과 같습니다.
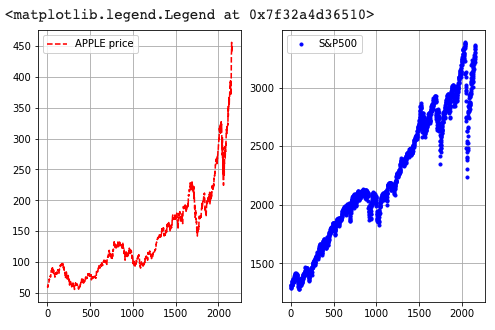
코드를 살펴보면 다음과 같습니다. 이 코드는 어떻게 표현이 될까요? 한번 알아보겠습니다.
- subplot(1,2,1)은 위의 함수 정의에서 나오는 것처럼 1행 2열 중 1첫번째 칸(1, 1) 라는 의미입니다.
- subplot(1,2,2)은 1행 2열중 2번째 칸(1, 2)라는 의미 입니다.
plt.figure(figsize=(8,5))
plt.subplot(1,2,1)
plt.plot(stock_df['AAPL'], 'r--')
plt.grid()
plt.legend(['APPLE price'])
plt.subplot(1,2,2)
plt.plot(stock_df['sp500'], 'b.')
plt.grid()
plt.legend(['S&P500'])시각화가 잘 표현 된 것을 볼 수 있습니다.
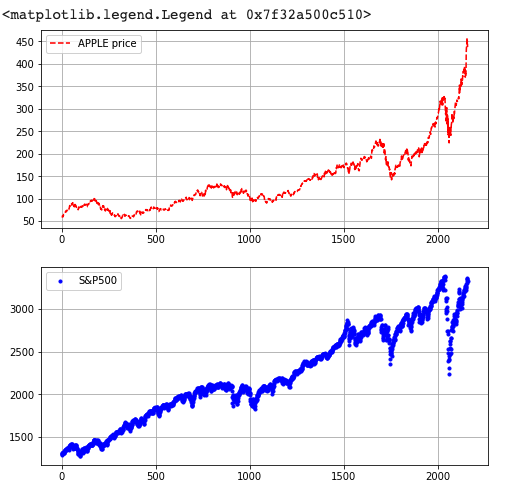
이번에는 수직으로 표현하는 방법을 살펴보겠습니다. 쉽습니다! subplot에서 행렬만 서로 바꿔주면 됩니다. 코드로 살펴보겠습니다.
- subplot(2,1,1)의 의미는 2행 1열 중 첫번째 칸 (1, 1)을 의미합니다.
- subplot(2,1,2)의 의미는 2행 1열 중 두번째 칸 (1, 2)을 의미합니다.
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(stock_df['AAPL'], 'r--')
plt.grid()
plt.legend(['APPLE price'])
plt.subplot(2,1,2)
plt.plot(stock_df['sp500'], 'b.')
plt.grid()
plt.legend(['S&P500'])시각화가 잘 표현 된 것을 볼 수 있습니다.
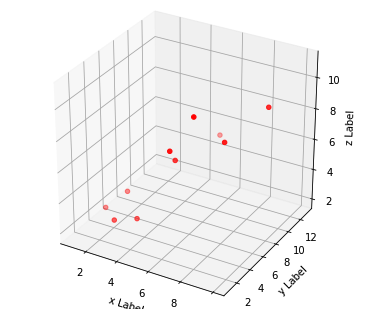
6. 3D Plot
matplot라이브러리 중에 Toolkits를 사용해야 합니다. 관련 내용은 하기 링크의 matplotlib 문서를 참고하시면 더욱 쉽게 이해하실수 있으실것 같습니다.
https://matplotlib.org/2.1.2/mpl_toolkits/index.html
Toolkits — Matplotlib 2.1.2 documentation
matplotlib.org
코드를 하나씩 보겠습니다.
- from mpl_toolkits.mplot3d import Axes3D는 기존 matplotlib가 아닌 mpl_toolkits 라이브러리에서 가져옵니다.
- 이전과 동일하게 figsize를 설정합니다.
- fig 객체에서 add_subplot함수를 설정합니다. 111의 의미는 1개(1, 1)의 그래프에 x,y,z를 넣겠다 라는 의미입니다.
- scatter(x,y,z)는 위에 설정한 x,y,z값의 데이터를 넣겠다는 의미입니다.
- c : Color / marker : 표시방법을 의미합니다.
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(111, projection='3d')
x = [1,2,3,4,5,6,7,8,9,10]
y = [5,6,2,3,13,4,1,2,4,8]
z = [2,3,3,3,5,7,9,11,9,10]
ax.scatter(x,y,z, c='r', marker='o')
ax.set_xlabel('x Label')
ax.set_ylabel('y Label')
ax.set_zlabel('z Label')이것을 그래프로 표현하면 다음과 같습니다.
7. Box Plot
Box Plot의 의미에 대해서 그림으로 잘 정리된 것이 있어 가져와 보았습니다. 이것을 참고하시면서 Box Plot에 대해서 그리면 좀 더 쉽게 이해가 되실 수 있으실 것이라고 생각합니다
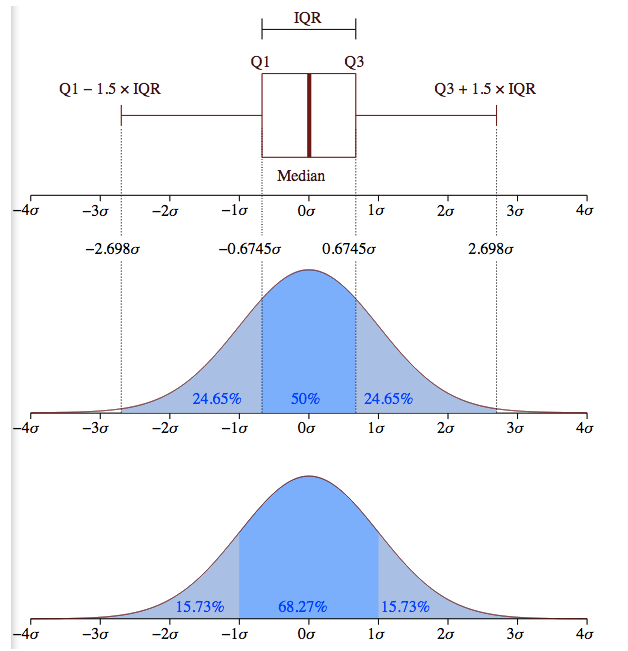
코드를 살펴보겠습니다.
- np.random.seed(20)의 의미는 사실 np.random.seed(seed=SEED)를 통해 넘기는 SEED라는 값은 그냥 난수를 뽑아내는 알고리즘인 Mersenne Twister에서 참고하는 ‘하나의 값’에 불과합니다. 쉽게 말하면 난수 생성 할 때 마다 값이 달라지는 것이 아니라, 누가, 언제 하든지 간에 똑같은 난수 생성을 원한다면 (즉, 재현가능성, reproducibility) seed 번호를 지정해주면 됩니다.
- np.random.normal(200,20,2000)의 의미는 평균 200, 표준편차 20 개수 2000개의 데이터를 추출하라 라는 뜻입니다.
- 그 아래는 위의 이미와 동일합니다.
- data_1,2,3,4를 data의 리스트로 묶어 boxplot의 데이터로 입력을 해줍니다
import numpy as np
np.random.seed(20)
data_1 = np.random.normal(200,20, 2000)
data_2 = np.random.normal(60,30, 2000)
data_3 = np.random.normal(70,20, 2000)
data_4 = np.random.normal(40,5, 2000)
data = [data_1,data_2, data_3, data_4]
fig = plt.figure(figsize=(10,7))
ax = fig.add_subplot(111)
bp = ax.boxplot(data)해당 코드를 실행하면 아래와 같이 잘 나오는 것을 확인 할 수 있습니다.
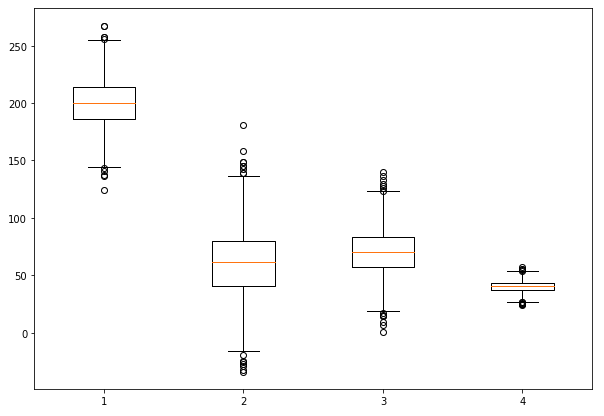
이상 파이썬 기초 중 하나인 matplotlib에 대해서 알아 보았습니다. 많은 분들에게 도움이 되었으면 좋겠습니다.
글을 읽어 주셔서 감사합니다.
'Data Scientist > Python' 카테고리의 다른 글
| [Python기초] Seaborn을 이용한 데이터 시각화 (0) | 2022.01.17 |
|---|---|
| [Python활용] Chrome Driver 설치 및 Selenium 활용 (3) | 2022.01.11 |
| [Python기초] Pandas (연산, 함수, Concat, Merge) (0) | 2022.01.05 |
| [Python활용] 텍스트 마이닝 - 네이버 API 이용신청 (0) | 2022.01.04 |
| [Python 기초] Pandas(dataframe만들기, CSV/HTML로 Data 불러오기) (0) | 2022.01.04 |