
삶의 공유
[금융데이터분석] 파이썬이용하여 코스피 대장주 찾기 Project-3(주가 DB저장) 본문
종목코드별 주가 데이터 크롤링하여 저장하기
※ 섹터 data MySQL Database에 저장하는 관련 포스팅은 하기 참고 바랍니다.
https://wg-cy.tistory.com/95?category=1023254
[금융] 파이썬이용하여 코스피 대장주 찾기 Project-2(섹터 DB저장)
업종 & 섹터 산출 1. 업종 분류 현황 크롤링 (코스피 상장사) ※ 업종 분류 현황 크롤링하는 자세한 방법에 대해서는 하기 포스팅 참고 하면 좋을것 같다 https://wg-cy.tistory.com/54?category=1023254..
wg-cy.tistory.com
1) Database에서 종목 코드 정보 가져오기
import pymysql
import pandas as pd
# MySQL에서 Investar DB에 접속
conn = pymysql.connect(host='localhost', user='root', passwd='여러분 비번', db='여러분 DB', charset='utf8')
sql = 'SELECT * FROM sector_info'
sector_table = pd.read_sql(sql, conn) # sector_info Table을 read_sql()함수로 읽는다.
code = sector_table['code'] # 종목 코드 정보만 별도로 분류한다.
code.head()
하나씩 살펴 보면
- MySQL의 기존에 Database에 저장해 두었던 섹터 정보 Data Table을 얻기 위해 Investar Database에 접근한다.
conn = pymysql.connect(host='localhost', user='root', passwd='여러분 비번', db='여러분 DB', charset='utf8')- Investar DB의 sector_info table에 데이터 내용을 전부 불러온다.
sql = 'SELECT * FROM sector_info'- Pandas 라이브러이의 read_sql함수로 해당 sql내용을 dataframe형태로 만든다.
sector_table = pd.read_sql(sql, conn)- 이중에서 code 정보만 별도로 분류해서 code라는 변수에 넣는다.
code = sector_table['code']
2) 네이버 금융에서 주가 데이터 가져오기
- 네이버 금융 홈페이지에 들어가서 종목을 검색한다. (예제는 삼성전자로 해보겠다.)
- 빨간색 네모박스 영역의 시세 버튼을 누른다.

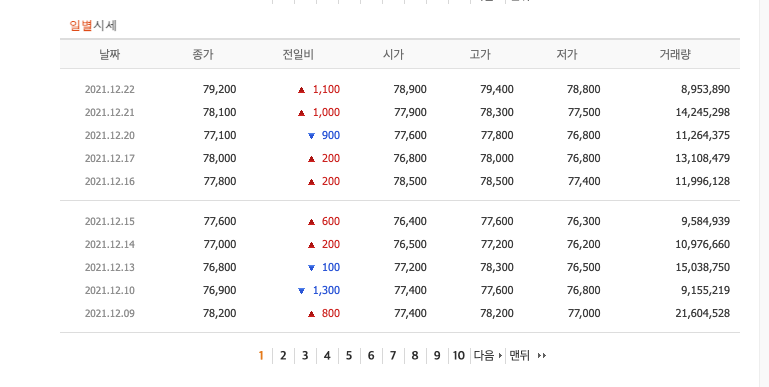
- 제일 아래 쪽에 일별 시세가 나와있는 것을 볼 수 있다.
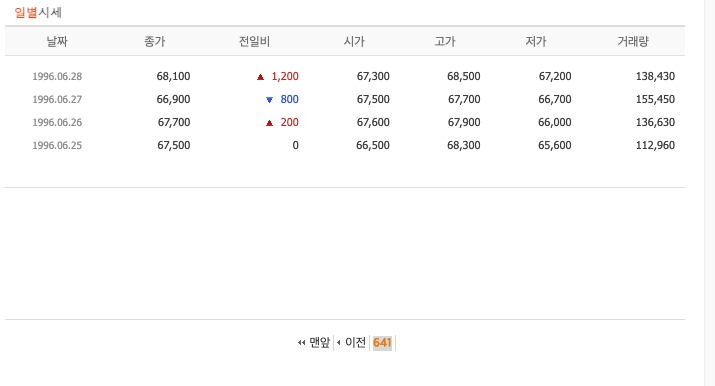
- "맨뒤" 버튼을 클릭한다.
- "641" 영역에 마우스를 대고 우클릭 -> 검사 클릭.
- 이렇게 파란색 영역으로 하이라이트 된것을 볼 수 있다. 이 곳을 클릭해보자

- 그럼 이렇게 별도 페이지가 나온다. 여기의 홈페이지 주소를 가져와보자.
: https://finance.naver.com/item/sise_day.naver?code=005930&page=641
: 여기서 view source를 볼수 있고, code=종목코드&page=page 숫자를 알수 있다.

- 자 이것을 기반으로 우리는 크롤링를 할 것이다. 우선 삼성 전자 주가 크롤링을 해보자
- 전체 코드는 이렇게 된다.
def read_naver(code):
try:
url = f"https://finance.naver.com/item/sise_day.nhn?code={code}"
headers = {'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Max OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.10. Safari/537.37'}
req = requests.get(url, headers=headers)
if req is None:
return None
html = BeautifulSoup(req.text, 'lxml')
pgrr = html.find('td', class_='pgRR')
if pgrr is None:
return None
lastpage = str(pgrr.a['href']).split('=')[-1]
df = pd.DataFrame()
pages_to_fetch = 5
pages = min(int(lastpage), pages_to_fetch)
for page in range(1, pages+1):
pg_url = requests.get('{}&page={}'.format(url, page), headers=headers)
df = pd.concat([df, pd.read_html(pg_url.text, encoding='euc-kr')[0]], ignore_index=True)
tmnow = datetime.now().strftime('%Y-%m-%d %H:%M')
print('[{}] {} : {:04d}/{:04d} pages are downloading...'.format(tmnow, code, page, pages), end="\r")
df = df.rename(columns={'날짜':'date', '종가':'close', '전일비':'diff', '시가':'open', '고가':'high', '저가':'low','거래량':'volume'})
df['date'] = df['date'].replace('.', '-')
df = df.dropna()
df[['close','diff','open','high','low','volume']] = df[['close','diff','open','high','low','volume']].astype(int)
df[['date','open','high','low','close','diff','volume']]
return df
except Exception as e:
print("예외 발생 : ", str(e))
return None결과도 이렇게 잘 나오는 것을 볼 수 있다.

하나씩 살펴보자
- 우리가 앞서 확인한 view-sourece를 url변수에 대입한다.
url = f"https://finance.naver.com/item/sise_day.nhn?code={code}"- 올해부터인가? 네이버에서 이제 header정보(접속자 컴퓨터의 정보)를 넣지 않으면 크롤링이 불가하다. 이에 따라서 header정보를 넣어주고 requests 라이브러리를 이용해서 정보를 받아 온다.
headers = {'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Max OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.10. Safari/537.37'}
req = requests.get(url, headers=headers)- 받아온 정보를 BeautifulSoup 라이브러리를 이용해서 lxml형식으로 읽어 드린 후 html변수에 대입한다.
html = BeautifulSoup(req.text, 'lxml')- BeutifulSoup 객체의 find함수를 이용해서 page 정보를 가져온다.
pgrr = html.find('td', class_='pgRR')
lastpage = str(pgrr.a['href']).split('=')[-1]
- 주가 정보를 담을 dataframe을 만든다.
df = pd.DataFrame()- page별로 data를 크롤링 하여, df에 담고 그것을 print함수를 통해 log로 남겨준다.
for page in range(1, pages+1):
pg_url = requests.get('{}&page={}'.format(url, page), headers=headers)
df = pd.concat([df, pd.read_html(pg_url.text, encoding='euc-kr')[0]], ignore_index=True)
tmnow = datetime.now().strftime('%Y-%m-%d %H:%M')
print('[{}] {} : {:04d}/{:04d} pages are downloading...'.format(tmnow, code, page, pages), end="\r")- 예외 발생시 내용을 아기위해 try, except 구문을 구현했고, 예외 내용에 대해서 print함수를 통해 남길수 있게 구현했다.
except Exception as e:
print("예외 발생 : ", str(e))
return None마지막으로 이렇게 만든 dataframe을 리턴하여 호출한 값에 대입할 수 있게 함수로 구현하였다.
3) 주가 Data를 MySQL Database에 저장하기
주가 데이터를 Database에 저장하기 위한 전체 코드이고, 함수로 구현하였다.
def replace_info_db(df, num, code, total):
with conn.cursor() as curs:
for r in df.itertuples():
# REPLACE를 INSERT처럼 사용 → 삽입하려는 내용중 기존 KEY가 없으면 INSERT와 동일하나 내용중 기존 KEY가 있으면 ROW 삭제후 삽입
sql = f"REPLACE INTO price_info VALUES ('{code}', "\
f"'{r.date}', {r.diff}, {r.daily_change}, {r.cumsum})"
curs.execute(sql)
conn.commit()
print('[{}] #{:04d} {} : {} rows > REPLACE INTO daily_price[OK]'.format(datetime.now().strftime('%Y-%m-%d %H:%M'), num+1, code, total))하나씩 살펴보자.
- itertuples는 행을 추출한다는 개념으로 이해하면되고, 간단한 예시를 보면
for r in df.itertuples():이렇게 pandas의 dataframe에서 padas형태로 출력되는 구문이다.
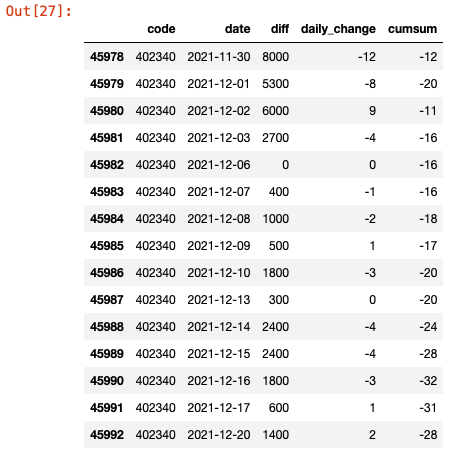
MySQL내의 price_info datatable에 각 행마다 접근한 컬럼들의 각 열들을 price_info테이블 내의 컬럼 순서에 맞춰 넣는다.
sql = f"REPLACE INTO price_info VALUES ('{code}', "\
f"'{r.date}', {r.diff}, {r.daily_change}, {r.cumsum})"
저장된 행들을 보자.
맨앞에 설명한 MySQL DB에서 code정보 가져오는 코드와 동일하다.
sql = 'SELECT * FROM price_info'
price_table = pd.read_sql(sql, conn) # sector_info Table을 read_sql()함수로 읽는다.
table = price_table["code"] == code[939]
table_df = price_table[table]
table_df이렇게 저장되었고 잘 나오는 것을 볼 수 있다.
code내의 전체 정보에 대해 각 함수들에 접근하여 DB에 저장하는 구문은 별도로 넣지는 않았는데, 이것은 여러분에 몫으로 남기겠다.
사실 별로 어렵지는 않다 for구문만 잘 맞추면된다.
그럼 다음 포스팅이 아마 이번 프로젝트의 마지막이 될 것 같다. 이렇게 Python으로 대장주 찾기 프로젝트 3번째 포스팅을 마치겠다.
'Data Scientist > Python' 카테고리의 다른 글
| [Python기초] Numpy A to Z (0) | 2022.01.02 |
|---|---|
| [금융데이터분석] 파이썬이용하여 코스피 대장주 찾기 Project(Final) (0) | 2021.12.22 |
| [금융데이터분석] 파이썬이용하여 코스피 대장주 찾기 Project-2(섹터 DB저장) (0) | 2021.12.12 |
| [금융] 파이썬이용하여 코스피 대장주 찾기 Project-1(코스피편) (0) | 2021.12.08 |
| [데이터수집] 한국 거래소 업종 분류 현황 및 개별 지표 크롤링 하기 (0) | 2021.10.27 |